Learn Traffic Crash as Language —— Datasets, Benchmarks and What-if Causal Analysis
Abstract
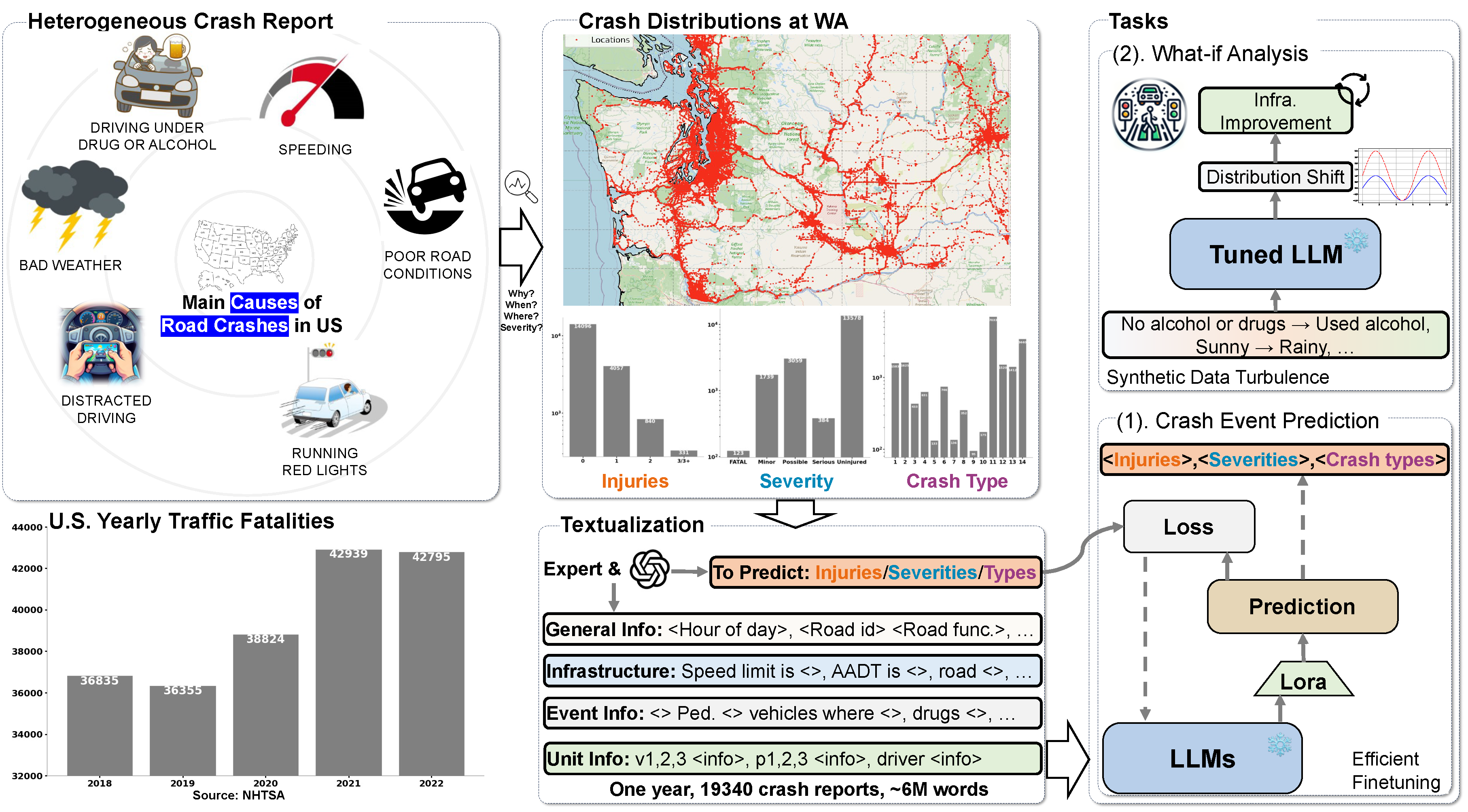
The increasing rate of road accidents worldwide results not only in significant loss of life but also imposes severe financial burdens on societies. Current research in traffic accident analysis has predominantly approached the problem as classification tasks, focusing mainly on learning-based classification or ensemble learning methods. These approaches often overlook the intricate relationships among the complex human and contextual factors related to traffic crashes and risky situations. In contrast, we initially formulate a large-scale traffic accident dataset consisting of abundant textual and visual information. We then present a novel application of large language models (LLMs) to enhance causal understanding and improve forecasting of traffic crash specifics, such as accident types and injury severity. Utilizing this rich dataset, we calibrate and fine-tune various LLM configurations to predict detailed accident outcomes based on contextual and environmental inputs. Our AccidentLLM diverges from traditional ensemble machine learning models by leveraging the inherent capabilities of LLMs to parse and learn from complex, unstructured data, thereby enabling a more nuanced analysis of contributing factors. Preliminary results indicate that our LLM-based approach not only predicts the severity of accidents but also classifies different types of accidents and predicts injury outcomes, all with an accuracy above 92%. We make our benchmark, datasets, and model public available for further exploration.
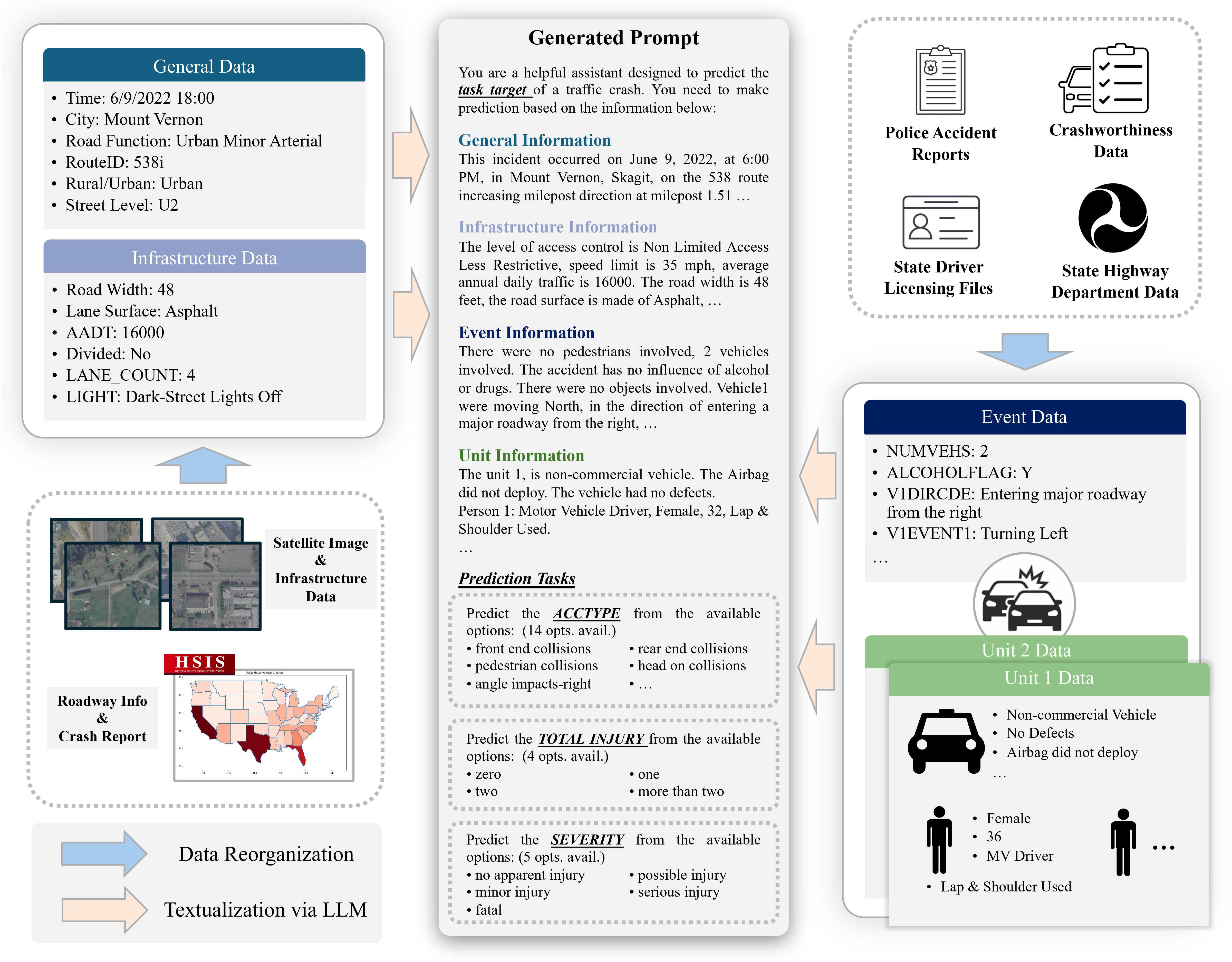
Summary of Prompt Design